[^RegEx is Easy]
Regex is short for regular expressions. They are used to validate and/or search for patterns in a given string or text in a flexible way using powerful syntax features like metacharacters.

![[^RegEx is Easy]](/content/images/size/w2000/2023/05/1_WdmbuDLGW1keqBUj3mWhsA.jpg)
RegEx is not hard, it just looks weird.
- Me
Regex is short for regular expressions. It makes working with text and implementing powerful search algorithms easy using metacharacters – but what are metacharacters? What is the regex syntax? What are some language-specific features regarding regex? Let's find out!
Meta Characters
Meta Characters are the characters that have some special meaning in the regex instead of their literal meaning, such as \, +, and so on.
\- The Backslash^- The Caret.- The Dot|- The Pipe$- The Dollar?- The Question Mark*- The Asterisks+- The Plus()- The Parentheses[]- The Square Brackets{}- The Curly Brackets
These are the primary metacharacters used in regex. Now, regex also has many character classes, anchors escaped characters, and more that leverage the power of metacharacters, so let's learn about them in detail.
\ – The Backslash
The Backslash character is used to escape other metacharacters or to indicate a sequence. Now what's that supposed to mean? In regex, some characters have superpowers, for example . can be used to find any character in the given string. We like to call them shorthand characters:

But what if we want to find the literal . character used in the string? \ can be used to "depower" the shorthand character in order to use it in it's literal meaning:

\ depowers some shorthand characters and metacharacters, but also gives new powers to characters – for example, \w, \d, \s, \W, \D, \S and more. \w \d \s is used to find any word, digit, or whitespace respectively, and \W \D \S is used to find anything that's not a word, digit, or whitespace respectively.
^ – The Caret
The caret is simple – it's used to anchor the regex to the beginning of a string or a line. This means that it matches the position before the first character of the string or the line. for example


Note: [^abc] means "neglect a/b/c"
. – The Dot
Well, the usage of . is already mentioned above, so there is nothing more to tell you about it. Or is there 🤔 The dot character is used to match any character ranging from a-z, A-Z, 0-9, and other escape characters except the newline character. We can use it to find our cat! :)

c.. will find any word that has 3 characters and starts with c.
| – The Pipe
The pipe is used to match or find either one of the given expressions. For example, a|b will match a or b. Simple, right? Here's an example of it's usage: let's say you have a word that starts with either c or h, and ends with at. For this purpose, we can use (c|h)at
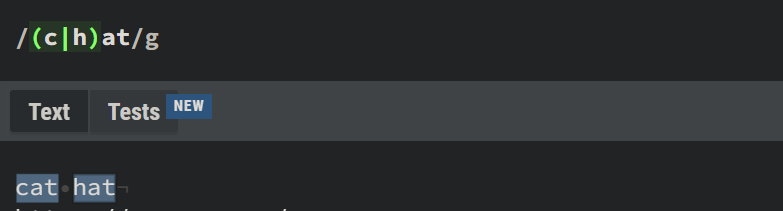
It can also be used for more complex decisions – for example, get a cat or dog?
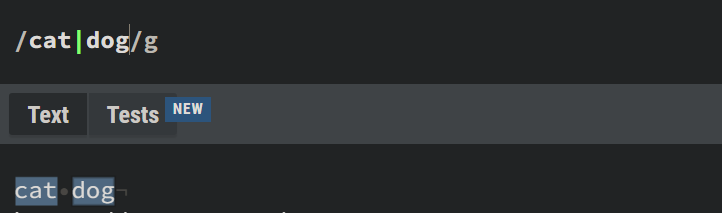
Moral: get both :)
$ – The Dollar
The dollar is used to match the end of the string or the end of the line if the multiline flag is enabled. Yeah, that's it.

? – The Question Mark
The question mark is used to match zero or one occurrence of the preceding element. In simpler words it lets you skip a character in a match. what does it mean again?
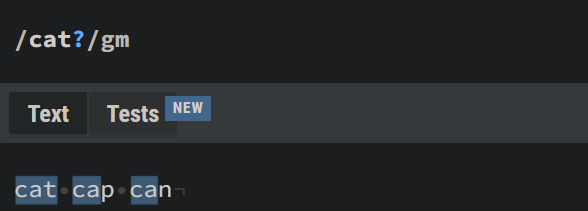
Here, we can use it to find a word that has 3 characters and the first two letters are c and a, where the third character is optionally a t.
* – The Asterisk
The asterisk is used to match zero or more occurrences of the preceding element. It's pretty similar to ?, with the difference being it matches zero or more occurences, whereas ? matches zero or one.
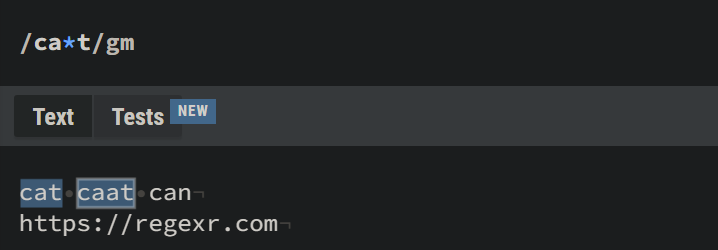
+ – The Plus
The plus is used to match one or more occurrences of the preceding element.

But wait...

Getting deja vu? you might be seeing a pattern in ?, *, and +. They are something called quantifiers. A quantifier indicates the number of times a character occurs in a sequence. We will learn more about them later.
() – The Parantheses
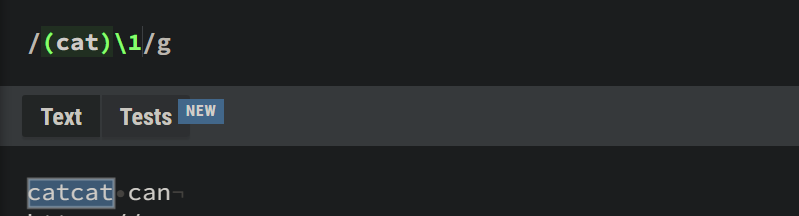
Parantheses are used to group multiple tokens together and create a group to extract the substring. Where can we use it? Let's say you want to find a word catcat but you are lazy to type cat twice. You can instead use (cat)\1. In this case, \1 is the first "captured group". A captured group is a set of characters that are matched in a set of parantheses, which here is cat.
[] – The Square Brackets
Square brackets can be used to create character classes. The characters in a character class can be specified individually or as a range to match the given set or range. For example, we can use [a-z] to match any character from a to z( case sensitive).

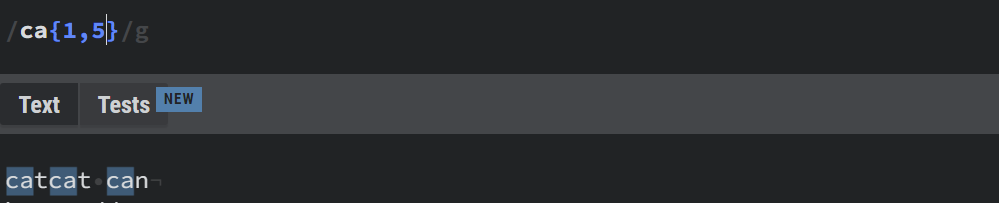
{} – The Curly Brackets
Remember we talked about Quantifiers above? The curly brackets are a more efficient way of quantifying. But wait.. what is a quantifier again? A quantifier tells the regex engine how many times a particular character or group of characters is to be matched. It also has many tricks under it's sleeve -- for example, {5} will quantify until 5 characters, {1,} will quantify one or more, and {1,5} will quantify in between 1 and 5.
Now that you have a basic idea of what metacharacters are, let's finally do something fun. Let's break down some useful regexes I found on the internet! :)
RegEx Breakdowns

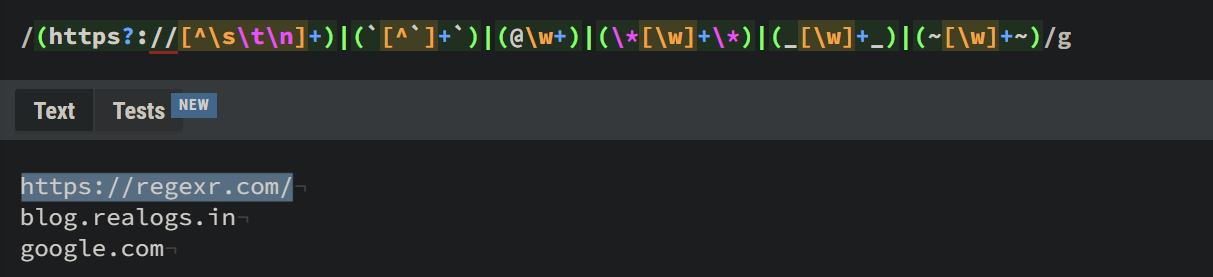
(https?://[^\s\t\n]+)|(`[^`]+`)|(@\w+)|(\*[\w]+\*)|(_[\w]+_)|(~[\w]+~)This very very simple-looking regex ;) is used to validate a URL. Let's see how it does that. As you can see, queries are divided into groups () of alternatives:
(https?:\/\/[^\s\t\n]+)- This block tells the regex engine that a URL must start with eitherhttporhttps. It then must match two forward slashes (//), and then match one or more of any character that is not a\s(whitespace),\t(tab), or a\n(newline) character.(`[^`]+`)- This is as simple as it looks - it allows a URL to be wrapped in`, which looks something like this`realogs`.in.(@\w+)- this matches a string that starts with an@followed by one or more words.(\*[\w]+\*) | (_[\w]+_) | (~[\w]+~)- These match*something*,_something_, and~something~respectively.
Now, this regex works, but if you try it with more valid URLs, you'll notice it doesn't match them.
So, Captain Regex, let's fix it!
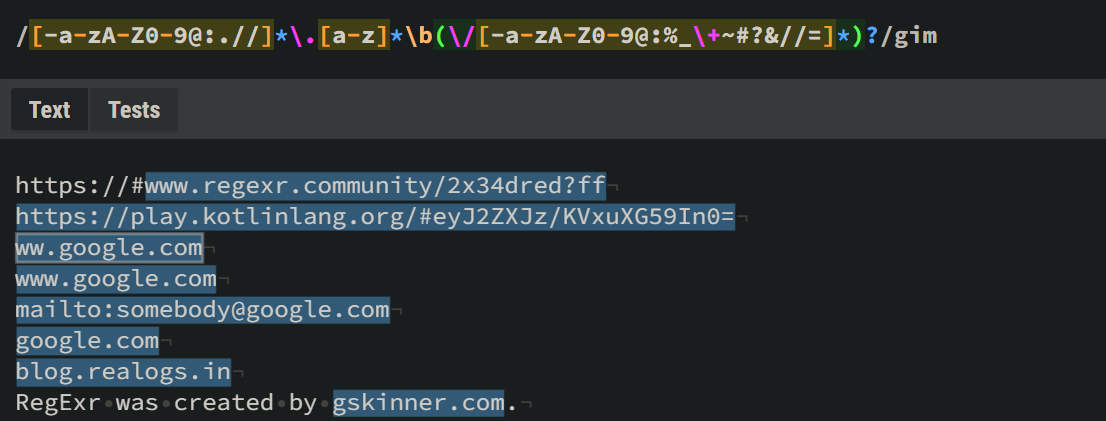
[-a-zA-Z0-9@:.//]*\.[a-z]*\b(\/[-a-zA-Z0-9@:%_\+~#?&//=]*)?[-a-zA-Z0-9@:.//]*- this part helps us validate the protocol and domain name. This approach has both pros and cons -- pros being that it allows us to validatemailto,ftpand more, and it also validates urls without protocol, thus validatingblog.realogs.in. However, a con would be that it also validatesww.google.com.\.[a-z]*- Here we set a condition for our TLD to validate only alphabets, and since we can have a TLD of arbitrary length like.communityor.in, we can either use*or set a hard limit of 2 or more using{2,}.\b(/[-a-zA-Z0-9@:%_+~#?&.//=]*)?- This final part allows URLs to be extended after/and be of any length using*. This also allows the URL to have multiple special characters like@#_?%=/. Appending?at the end makes the extended page optional.
Language Feature
In Kotlin, a language I'm quite fond of, there are numerous powerful regex features. In Kotlin, you can create a regex using either "your pattern".toRegex() or Regex("Pattern", Regex Option). Kotlin also has many regex features, like:
RegexOption.CANON_EQ- This enables equivalence by canonical decomposition. An important note is that this flag is not supported on Android.RegexOption.COMMENTS- This permits whitespace and comments in the regex.RegexOption.DOT_MATCHES_ALL- This makes.match even line terminators, and other characters that it usually does not.RegexOption.IGNORE_CASE- This enables case-insensitive matching. Case comparison is Unicode-aware.RegexOption.LITERAL- This enables literal parsing of the regex. This means that metacharacters or escape sequences in the input sequence will be given no special meaning and considered as-is.RegexOption.MULTILINE- In multiline mode the expressions^and$match just after or just before, respectively, a line terminator or the end of the input sequence.RegexOption.UNIX_LINES- Enables Unix lines mode. In this mode, only\nis recognized as a line terminator.
Kotlin also has multiple other helpful regex related functions and utilities, which you can check out here.
Conclusion
Regex is an incredibly powerful tool that can be a game-changer when it comes to working with text. It simplifies tasks like pattern matching, text extraction, validation, cleaning, replacement, and parsing. With its language-specific features and compatibility across various platforms, regex makes your life easier and saves you a ton of time.
Not only does regex automate repetitive tasks, but it also handles strings efficiently. So, taking the time to learn regex is definitely worth it. It opens up a world of possibilities and can greatly improve your productivity.
To make things even better, I've included some bonus links to helpful tools that can complement your regex skills. Feel free to check them out and let me know what you think. Your feedback is important to me as it helps me improve the blog and provide even more valuable content. :)
Bonus Links
Official documentations:



Learn about canvas in Jetpack Compose:

New to Kotlin?

Get to learn about coroutines:

Wanna try something cross-platform?